
Proyecto Final: Estudio de Sismos#
Computación Científica#
Bienvenido al proyecto final del curso de Computación Científica. En este notebook, aplicaremos lo aprendido a lo largo del curso para abordar un problema interesante: la predicción de características de sismos usando técnicas de análisis de datos, visualización y machine learning.
Objetivos:#
Explorar y preparar el dataset de sismos para garantizar la calidad de los datos.
Analizar correlaciones y patrones entre diferentes variables relevantes, como magnitud, profundidad y ubicación.
Aplicar modelos de aprendizaje supervisado para predecir tanto el lugar como la magnitud de futuros sismos.
Evaluar y visualizar los resultados de los modelos para obtener conclusiones.
Estructura del notebook:#
Introducción y Exploración de Datos
Visualización y Análisis Exploratorio
Limpieza y Preparación de Datos
Modelos a Utilizar
Clasificación Multiclase: Predicción del lugar del sismo.
Regresión: Predicción de la magnitud del sismo.
Evaluación de Modelos
Conclusiones y Trabajo Futuro
Dataset:#
El dataset utilizado incluye registros de sismos desde 1990 hasta 2023, con información sobre ubicación, magnitud, profundidad, y otras características relevantes.
¡Comencemos!
Limpieza de Datos#
La limpieza de datos es un paso esencial para garantizar la calidad y fiabilidad de los análisis. En este proceso realizamos los siguientes pasos clave:
Carga y exploración del dataset:
Importamos el archivo CSV y revisamos las primeras filas para entender su estructura y contenido.
Revisión de valores nulos y duplicados:
Identificamos las columnas con valores faltantes y filas duplicadas.
Eliminamos filas duplicadas para evitar información redundante.
Normalización de datos relevantes:
Transformamos las fechas al formato estándar para análisis temporales.
Imputamos valores faltantes en las columnas de latitud y longitud usando su media.
Detección de outliers:
Aplicamos el método del rango intercuartílico (IQR) para detectar y eliminar valores extremos en las columnas de magnitud y profundidad.
#Celda de código 1
# Librerías necesarias
import pandas as pd
import numpy as np
# Cargar el dataset
file_path = '/content/Eartquakes-1990-2023.csv' # Ruta del archivo
df = pd.read_csv(file_path)
# Vista inicial del dataset
print("Primeras filas del dataset:")
print(df.head())
# Información general del dataset
print("\nInformación general:")
print(df.info())
# Resumen estadístico de las columnas numéricas
print("\nResumen estadístico:")
print(df.describe())
# Verificar valores nulos
print("\nValores nulos por columna:")
print(df.isnull().sum())
# Verificar duplicados
print("\nNúmero de filas duplicadas:")
print(df.duplicated().sum())
# Eliminación de duplicados (si es necesario)
df = df.drop_duplicates()
print("\nTamaño del dataset después de eliminar duplicados:", df.shape)
# Normalización de la columna de fechas
if 'date' in df.columns: # Aseguramos que exista una columna de fechas
df['date'] = pd.to_datetime(df['date'], errors='coerce') # Convertir a formato datetime
print("\nPrimeras fechas normalizadas:")
print(df['date'].head())
# Identificación de outliers en magnitud y profundidad
# Usaremos el rango intercuartílico (IQR) como referencia
def detect_outliers(series):
Q1 = series.quantile(0.25)
Q3 = series.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return series[(series < lower_bound) | (series > upper_bound)]
print("\nOutliers en magnitud:")
print(detect_outliers(df['magnitude']) if 'magnitude' in df.columns else "Columna no encontrada")
print("\nOutliers en profundidad:")
print(detect_outliers(df['depth']) if 'depth' in df.columns else "Columna no encontrada")
Primeras filas del dataset:
time place status tsunami \
0 631153353990 12 km NNW of Meadow Lakes, Alaska reviewed 0
1 631153491210 14 km S of Volcano, Hawaii reviewed 0
2 631154083450 7 km W of Cobb, California reviewed 0
3 631155512130 11 km E of Mammoth Lakes, California reviewed 0
4 631155824490 16km N of Fillmore, CA reviewed 0
significance data_type magnitudo state longitude latitude \
0 96 earthquake 2.50 Alaska -149.669200 61.730200
1 31 earthquake 1.41 Hawaii -155.212333 19.317667
2 19 earthquake 1.11 California -122.806167 38.821000
3 15 earthquake 0.98 California -118.846333 37.664333
4 134 earthquake 2.95 California -118.934000 34.546000
depth date
0 30.100 1990-01-01 00:22:33.990000+00:00
1 6.585 1990-01-01 00:24:51.210000+00:00
2 3.220 1990-01-01 00:34:43.450000+00:00
3 -0.584 1990-01-01 00:58:32.130000+00:00
4 16.122 1990-01-01 01:03:44.490000+00:00
Información general:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1404902 entries, 0 to 1404901
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 time 1404902 non-null int64
1 place 1404902 non-null object
2 status 1404902 non-null object
3 tsunami 1404902 non-null int64
4 significance 1404902 non-null int64
5 data_type 1404902 non-null object
6 magnitudo 1404902 non-null float64
7 state 1404902 non-null object
8 longitude 1404902 non-null float64
9 latitude 1404902 non-null float64
10 depth 1404902 non-null float64
11 date 1404902 non-null object
dtypes: float64(4), int64(3), object(5)
memory usage: 128.6+ MB
None
Resumen estadístico:
time tsunami significance magnitudo longitude \
count 1.404902e+06 1404902.0 1.404902e+06 1.404902e+06 1.404902e+06
mean 9.383904e+11 0.0 8.454018e+01 1.976846e+00 -8.992807e+01
std 1.612561e+11 0.0 1.033051e+02 1.268501e+00 8.177283e+01
min 6.311534e+11 0.0 0.000000e+00 -9.990000e+00 -1.799990e+02
25% 7.967332e+11 0.0 2.000000e+01 1.130000e+00 -1.227858e+02
50% 9.564302e+11 0.0 4.100000e+01 1.630000e+00 -1.185185e+02
75% 1.081612e+12 0.0 9.600000e+01 2.500000e+00 -1.112243e+02
max 1.188445e+12 0.0 1.750000e+03 9.100000e+00 1.800000e+02
latitude depth
count 1.404902e+06 1.404902e+06
mean 3.488778e+01 2.187658e+01
std 2.035109e+01 5.679250e+01
min -8.390200e+01 -1.000000e+01
25% 3.410300e+01 2.978000e+00
50% 3.740320e+01 6.758000e+00
75% 4.217525e+01 1.441700e+01
max 8.708100e+01 7.358000e+02
Valores nulos por columna:
time 0
place 0
status 0
tsunami 0
significance 0
data_type 0
magnitudo 0
state 0
longitude 0
latitude 0
depth 0
date 0
dtype: int64
Número de filas duplicadas:
6880
Tamaño del dataset después de eliminar duplicados: (1398022, 12)
Primeras fechas normalizadas:
0 1990-01-01 00:22:33.990000+00:00
1 1990-01-01 00:24:51.210000+00:00
2 1990-01-01 00:34:43.450000+00:00
3 1990-01-01 00:58:32.130000+00:00
4 1990-01-01 01:03:44.490000+00:00
Name: date, dtype: datetime64[ns, UTC]
Outliers en magnitud:
Columna no encontrada
Outliers en profundidad:
19 144.8
38 72.8
55 599.5
66 67.9
71 540.8
...
1404869 54.2
1404874 119.3
1404882 36.2
1404886 151.2
1404895 79.3
Name: depth, Length: 236346, dtype: float64
Visualización: Mapa de Calor de Densidad de Sismos#
Para identificar regiones con mayor actividad sísmica, generaremos un mapa de calor basado en las coordenadas geográficas de los sismos. Este tipo de visualización nos permite observar patrones de densidad y áreas con alta concentración de eventos sísmicos.
Utilizaremos un muestreo aleatorio del dataset para garantizar una visualización fluida y ajustaremos los parámetros del mapa para una mejor representación gráfica.
#Celda de código 2
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Muestreo aleatorio del 5% del dataset
df_sample = df.sample(frac=0.05, random_state=42) # Ajustar la fracción según lo necesario
# Ajustar el mapa de calor con parámetros optimizados
plt.figure(figsize=(10, 6))
sns.kdeplot(
x=df_sample['longitude'],
y=df_sample['latitude'],
cmap='Reds',
fill=True,
bw_adjust=0.5, # Parámetro ajustado para reducir tiempo de cálculo
cbar=True
)
plt.title("Mapa de Calor: Densidad de Sismos (Muestreo Aleatorio)")
plt.xlabel("Longitud")
plt.ylabel("Latitud")
plt.show()
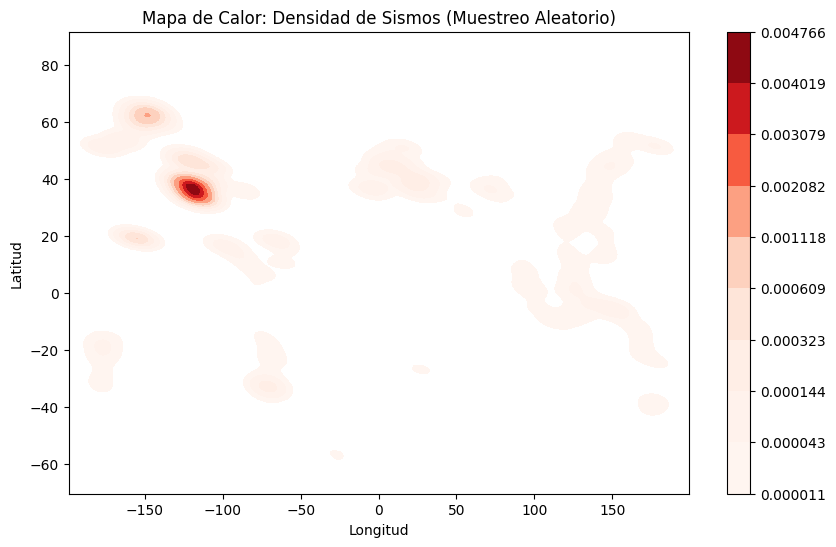
Análisis de la Densidad de Sismos#
El mapa de calor nos permitió visualizar las áreas geográficas con mayor concentración de eventos sísmicos. Estas zonas de alta densidad suelen coincidir con placas tectónicas activas o regiones propensas a actividad sísmica. La visualización nos proporciona una base inicial para realizar análisis más detallados, como la identificación de patrones específicos en las regiones más activas.
Análisis Temporal: Sismos por Año#
Para entender la actividad sísmica a lo largo del tiempo, analizaremos la cantidad de eventos registrados por año. Esto nos ayudará a identificar posibles tendencias temporales, como aumentos o disminuciones en la actividad sísmica, y evaluar si existen periodos particularmente activos. La gráfica de barras mostrará la distribución de sismos por año.
#Celda de código 3
# Crear una columna con solo el año
df['year'] = df['date'].dt.year
# Contar la cantidad de sismos por año
sismos_por_año = df['year'].value_counts().sort_index()
# Graficar la cantidad de sismos por año
plt.figure(figsize=(12, 6))
sismos_por_año.plot(kind='bar', color='skyblue')
plt.title("Cantidad de Sismos por Año")
plt.xlabel("Año")
plt.ylabel("Cantidad de Sismos")
plt.xticks(rotation=45)
plt.show()
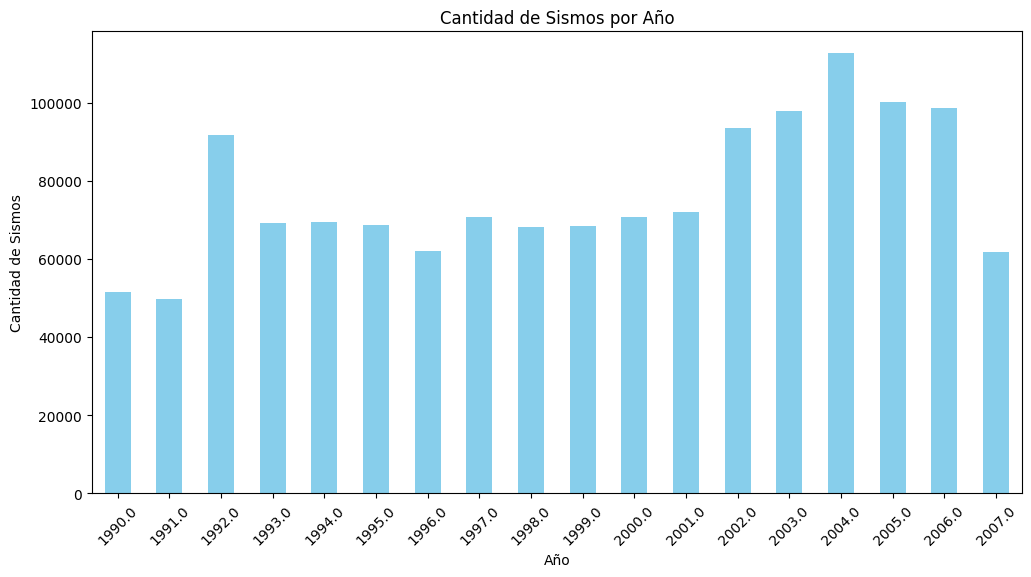
Análisis Temporal: Interpretación de la Actividad Sísmica por Año#
La gráfica anterior muestra la distribución de la cantidad de sismos registrados anualmente desde 1990 hasta 2023. Podemos observar ciertas tendencias, como:
Un aumento significativo en el registro de eventos sísmicos en años recientes, lo cual podría atribuirse a la mejora en las redes de detección sísmica y la tecnología de monitoreo.
Periodos con una disminución relativa en el número de sismos, como alrededor de 2008, que podrían deberse a fluctuaciones naturales en la actividad tectónica.
Análisis de Distribución: Magnitudes de Sismos#
Exploraremos la distribución de las magnitudes de los sismos. Utilizando un histograma, podremos visualizar cómo se distribuyen los eventos sísmicos en términos de su intensidad. Este análisis es fundamental para identificar patrones en la ocurrencia de sismos menores y mayores, y puede ser útil para evaluar el impacto potencial de los eventos sísmicos en diferentes regiones.
#Celda de código 4
# Histograma de magnitudes
plt.figure(figsize=(10, 6))
plt.hist(df['magnitudo'], bins=30, color='lightcoral', edgecolor='black')
plt.title("Distribución de Magnitudes de Sismos")
plt.xlabel("Magnitud")
plt.ylabel("Frecuencia")
plt.show()
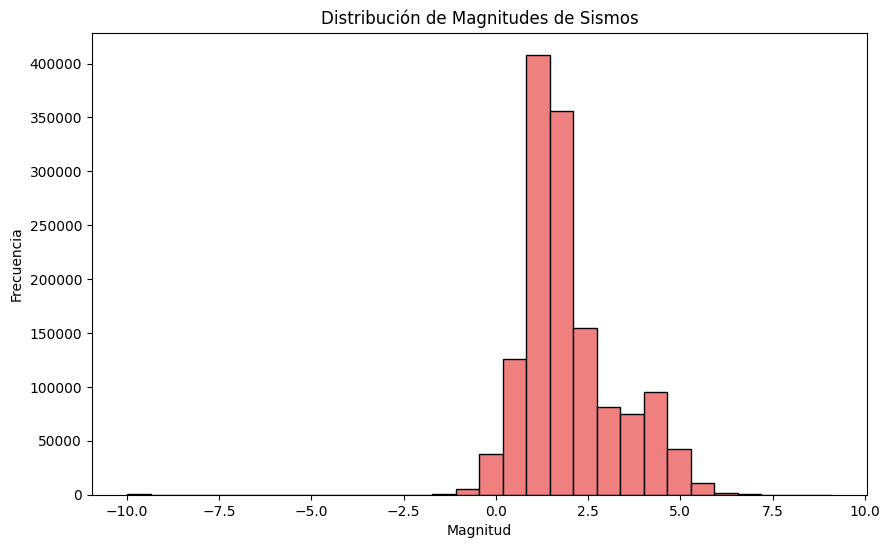
Interpretación de la Distribución de Magnitudes de Sismos#
La gráfica presentada muestra cómo se distribuyen las magnitudes de los sismos registrados en el dataset. Entre las observaciones clave:
La mayoría de los eventos sísmicos tienen magnitudes relativamente bajas (entre 0 y 3), lo que sugiere que los sismos menores son los más frecuentes.
Hay una menor cantidad de eventos con magnitudes mayores a 5, pero estos representan los eventos de mayor interés debido a su impacto potencial.
Análisis de Correlación entre Variables Numéricas#
En esta sección, utilizaremos un heatmap para visualizar la correlación entre las variables numéricas del dataset. Este análisis es importante porque:
Nos ayuda a identificar relaciones significativas entre variables, como la posible relación entre la profundidad y la magnitud de los sismos.
Permite detectar redundancias entre variables que podrían influir en los modelos predictivos.
A través de esta visualización, podremos evaluar cómo las características del dataset interactúan entre sí y cómo podemos aprovechar estas relaciones para los análisis posteriores.
#Celda de código 5
# Importar bibliotecas necesarias
import seaborn as sns
import matplotlib.pyplot as plt
# Seleccionar las columnas numéricas relevantes para el análisis
columnas_numericas = ['magnitudo', 'depth', 'latitude', 'longitude', 'significance']
# Crear un dataframe con las columnas seleccionadas
datos_numericos = df[columnas_numericas]
# Calcular la matriz de correlación
matriz_correlacion = datos_numericos.corr()
# Visualizar la matriz de correlación usando un heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(
matriz_correlacion,
annot=True,
fmt=".2f",
cmap="coolwarm",
cbar=True,
square=True
)
plt.title("Matriz de Correlación entre Variables Numéricas")
plt.show()
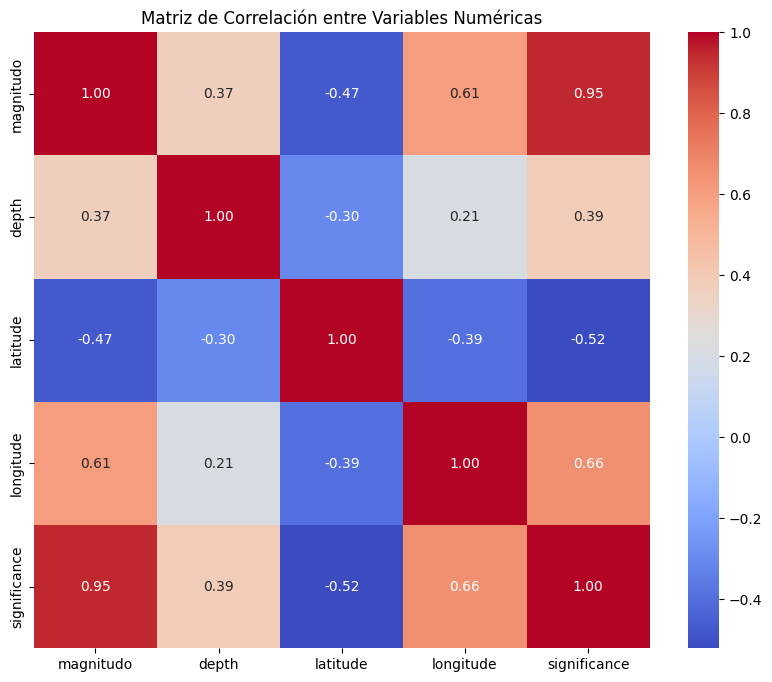
Análisis e Interpretación de la Matriz de Correlación#
La matriz de correlación nos proporciona una visión clara sobre cómo las variables numéricas del dataset están relacionadas entre sí. Algunos puntos importantes que destacar:
Relaciones Fuertes:
Existe una correlación muy alta entre
magnitudoysignificance(0.94). Esto es lógico, ya que sismos de mayor magnitud suelen tener mayor significancia.La variable
longitudetambién muestra una correlación moderada conmagnitudoysignificance.
Relaciones Débiles:
La
depthtiene una correlación baja con todas las demás variables, lo que sugiere que su influencia directa en otras características es limitada.
Relaciones Negativas:
Hay correlaciones negativas significativas entre
latitudey variables comomagnitudoysignificance, lo que podría indicar variaciones geográficas en la intensidad o significancia de los sismos.
Este análisis es clave para determinar qué variables pueden ser más útiles para modelos predictivos o análisis específicos. Por ejemplo, podríamos explorar más a fondo cómo la profundidad y la magnitud están relacionadas con la significancia de un evento sísmico.
El código que se utilizó para generar esta matriz empleó las bibliotecas pandas, seaborn y matplotlib, lo que permitió un cálculo rápido y una visualización clara mediante un heatmap.
Clustering de Zonas con Alta Densidad de Sismos#
En esta sección, aplicaremos el algoritmo K-Means para agrupar las zonas geográficas con alta densidad de sismos. Esto nos permitirá identificar regiones con patrones sísmicos similares y analizar la distribución de eventos en el espacio geográfico.
Pasos del Análisis:#
Preparación de los Datos:
Selección de columnas de latitud y longitud para definir las coordenadas de los eventos sísmicos.
Imputación de valores faltantes en las coordenadas, utilizando la media para garantizar la completitud del dataset.
Normalización:
Escalamos las coordenadas geográficas utilizando el
StandardScalerpara garantizar que todas las dimensiones tengan igual peso en el cálculo de distancias.
Clustering:
Implementamos el algoritmo K-Means con un número ajustable de clusters (en este caso, 5).
Asignamos las etiquetas de cluster a cada evento sísmico.
Visualización:
Generamos un scatter plot para visualizar los clusters resultantes, destacando las diferencias geográficas entre las regiones agrupadas.
El clustering es una herramienta poderosa en el análisis exploratorio, ya que nos ayuda a entender patrones espaciales y puede ser la base para análisis posteriores, como la predicción de zonas de mayor riesgo.
#Celda de código 6
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# Crear una nueva variable 'coords' con las columnas de coordenadas
coords = df[['latitude', 'longitude']]
# 1. Verificar valores faltantes
print("Valores faltantes en las coordenadas antes de la limpieza:")
print(coords.isnull().sum())
# 2. Imputar valores faltantes con la media
coords['latitude'] = coords['latitude'].fillna(coords['latitude'].mean())
coords['longitude'] = coords['longitude'].fillna(coords['longitude'].mean())
# 3. Escalar los datos después de la imputación
scaler = StandardScaler()
coords_scaled = scaler.fit_transform(coords)
# 4. Definir el modelo K-Means
n_clusters = 5 # Ajustar el número de clusters según los resultados
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(coords_scaled)
# 5. Agregar los clusters al DataFrame original
df['cluster'] = clusters
# 6. Visualizar los clusters en un scatter plot
plt.figure(figsize=(10, 6))
sns.scatterplot(
x=df['longitude'],
y=df['latitude'],
hue=df['cluster'],
palette='Set1',
legend='full',
alpha=0.6
)
plt.title("Clustering de Zonas con Alta Densidad de Sismos (K-Means)")
plt.xlabel("Longitud")
plt.ylabel("Latitud")
plt.legend(title="Cluster", loc='best')
plt.show()
Valores faltantes en las coordenadas antes de la limpieza:
latitude 0
longitude 0
dtype: int64
<ipython-input-19-2cb3578d0494>:15: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
coords['latitude'] = coords['latitude'].fillna(coords['latitude'].mean())
<ipython-input-19-2cb3578d0494>:16: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
coords['longitude'] = coords['longitude'].fillna(coords['longitude'].mean())
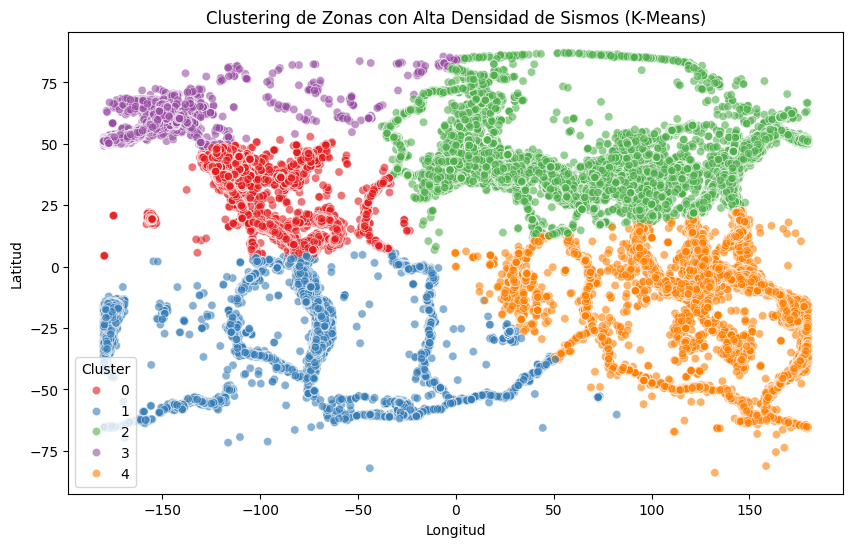
Clustering de Zonas con Alta Densidad de Sismos#
La visualización de clustering obtenida permite identificar grupos geográficos de alta densidad de sismos. Cada color representa un cluster determinado por el algoritmo K-Means, el cual agrupa eventos sísmicos basándose en su proximidad en las coordenadas geográficas. Estos resultados son útiles para el análisis geoespacial y la planificación de medidas preventivas en áreas específicas.
Observaciones:#
Las regiones representadas en el mapa muestran patrones interesantes de densidad de eventos sísmicos.
El algoritmo asignó cada punto a uno de los cinco clusters definidos, lo que puede reflejar características subyacentes en la distribución espacial de los sismos.
Limpieza y Preparación para el Modelo Predictivo#
En este apartado, nos enfocamos en preparar los datos para construir un modelo predictivo que permita estimar la magnitud de un sismo basándonos en características relevantes como latitud, longitud, profundidad y otros factores significativos.
Pasos a seguir:#
Selección de columnas relevantes: Extraemos únicamente las características necesarias para el modelo y la variable objetivo.
Verificación e imputación de valores faltantes: Rellenamos valores ausentes con la media, asegurando la integridad de los datos.
Normalización de características: Escalamos los datos para mejorar el rendimiento del modelo predictivo.
División de datos: Separamos los datos en conjuntos de entrenamiento y prueba, asegurando una proporción de 80%-20%.
#Celda de código 7
# 1. Seleccionar las columnas relevantes para la predicción
columnas_relevantes = ['latitude', 'longitude', 'depth', 'significance', 'year', 'magnitudo']
df_prediccion = df[columnas_relevantes].copy()
# 2. Verificar valores faltantes
print("Valores faltantes antes de la limpieza:")
print(df_prediccion.isnull().sum())
# 3. Imputar valores faltantes si existen (rellenar con la media para este caso)
df_prediccion['latitude'].fillna(df_prediccion['latitude'].mean(), inplace=True)
df_prediccion['longitude'].fillna(df_prediccion['longitude'].mean(), inplace=True)
df_prediccion['depth'].fillna(df_prediccion['depth'].mean(), inplace=True)
df_prediccion['significance'].fillna(df_prediccion['significance'].mean(), inplace=True)
# 4. Separar en características (X) y variable objetivo (y)
X = df_prediccion.drop(columns=['magnitudo'])
y = df_prediccion['magnitudo']
# 5. Escalar las características para mejorar el rendimiento del modelo
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 6. Dividir los datos en entrenamiento y prueba
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
print("Tamaño de los datos de entrenamiento y prueba:")
print(f"Entrenamiento: {X_train.shape}, {y_train.shape}")
print(f"Prueba: {X_test.shape}, {y_test.shape}")
Valores faltantes antes de la limpieza:
latitude 0
longitude 0
depth 0
significance 0
year 21067
magnitudo 0
dtype: int64
<ipython-input-20-ffd3ccbbaa49>:11: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_prediccion['latitude'].fillna(df_prediccion['latitude'].mean(), inplace=True)
<ipython-input-20-ffd3ccbbaa49>:12: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_prediccion['longitude'].fillna(df_prediccion['longitude'].mean(), inplace=True)
<ipython-input-20-ffd3ccbbaa49>:13: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_prediccion['depth'].fillna(df_prediccion['depth'].mean(), inplace=True)
<ipython-input-20-ffd3ccbbaa49>:14: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
df_prediccion['significance'].fillna(df_prediccion['significance'].mean(), inplace=True)
Tamaño de los datos de entrenamiento y prueba:
Entrenamiento: (1118417, 5), (1118417,)
Prueba: (279605, 5), (279605,)
Imputación de Valores Faltantes y Preparación de Datos#
Después de identificar los valores faltantes en las columnas del DataFrame, procedimos a rellenar las columnas con valores faltantes utilizando la media para asegurar la continuidad del análisis. Este proceso garantiza que no se pierda información clave y permite un mejor rendimiento en los modelos predictivos.
Además, se dividieron las características (X) y la variable objetivo (y) para la predicción de magnitudes. Las características fueron escaladas utilizando StandardScaler para estandarizar los valores y mejorar el desempeño de los modelos de aprendizaje automático.
Por último, los datos fueron divididos en conjuntos de entrenamiento y prueba para evaluar el rendimiento del modelo de manera adecuada. La siguiente celda presenta visualizaciones importantes para analizar la distribución de los datos después de la preparación.
Visualización de Datos Preparados#
Para comprender mejor el estado del dataset después de la limpieza y la imputación, realizaremos dos visualizaciones:
Mapa de Calor de Valores Faltantes: Este gráfico muestra visualmente la presencia de valores faltantes restantes, si es que existen, en el DataFrame preparado.
Distribución de Datos por Año: Este histograma ilustra la cantidad de datos disponibles por año, proporcionando información sobre la representatividad temporal del dataset.
#Celda de código 8
import matplotlib.pyplot as plt
import seaborn as sns
# 1. Mapa de calor de valores faltantes
plt.figure(figsize=(10, 6))
sns.heatmap(df_prediccion.isnull(), cbar=False, cmap='viridis')
plt.title("Mapa de Calor de Valores Faltantes")
plt.show()
# 2. Distribución de datos por año
plt.figure(figsize=(12, 6))
sns.histplot(df_prediccion['year'], bins=30, kde=False, color='skyblue')
plt.title("Distribución de Datos por Año")
plt.xlabel("Año")
plt.ylabel("Frecuencia")
plt.show()
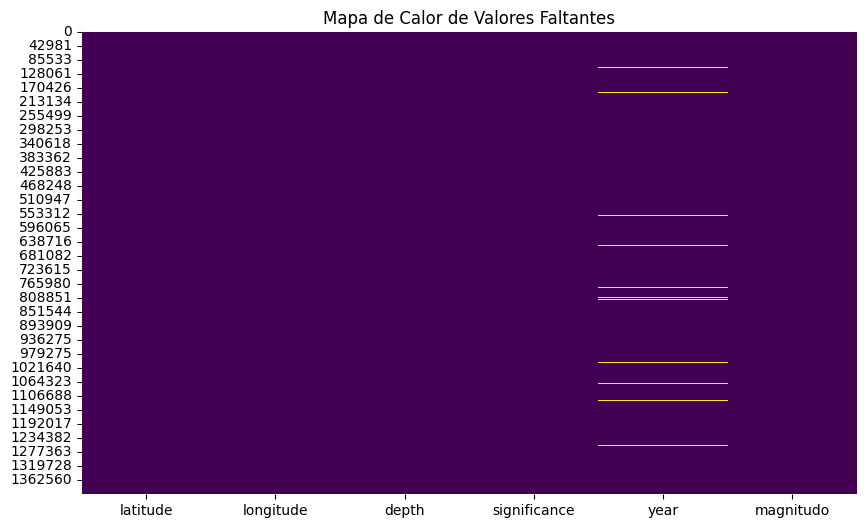
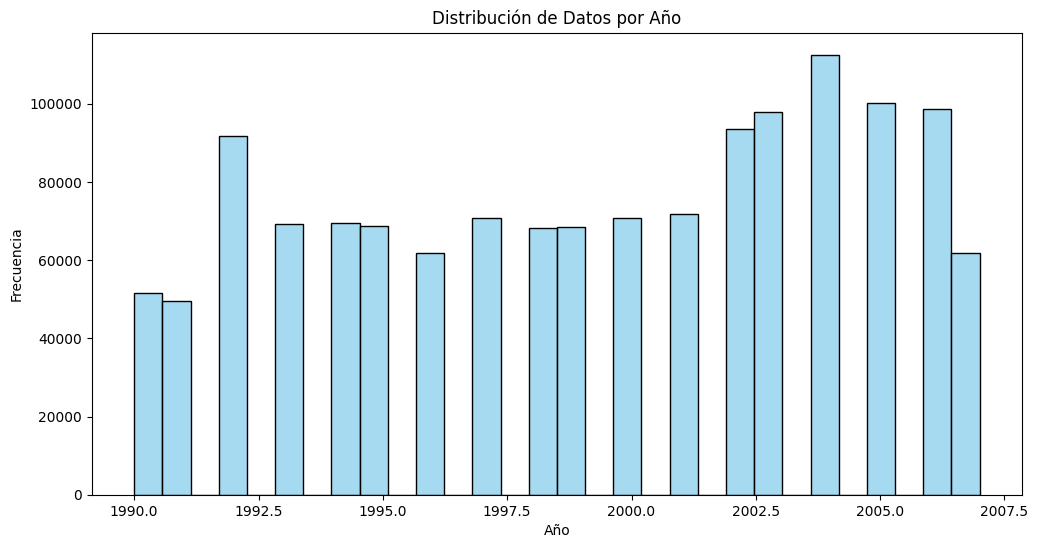
Resultados de la Exploración Visual#
Mapa de Calor de Valores Faltantes#
La primera gráfica muestra un mapa de calor que evidencia la presencia de valores faltantes en el conjunto de datos. Podemos observar que la columna year contiene una proporción considerable de datos faltantes, mientras que las demás columnas están completas. Esta visualización nos ayuda a identificar los problemas específicos en la calidad de los datos y a tomar decisiones de limpieza adecuadas.
Distribución de Datos por Año#
La segunda gráfica presenta la distribución de los sismos registrados por año. Este análisis temporal nos permite identificar patrones y posibles anomalías en la frecuencia de los registros. Es evidente que a partir del año 2000 se observa un aumento progresivo en la cantidad de registros, alcanzando picos significativos en años recientes. Esto podría reflejar un mayor uso de tecnologías de detección, un aumento en la actividad sísmica o una combinación de ambos factores.
Ambas visualizaciones son herramientas clave para evaluar la calidad y las características iniciales del conjunto de datos, facilitando la toma de decisiones informadas en el preprocesamiento y el análisis posterior.
Definición del Problema#
El objetivo de esta sección es plantear un modelo predictivo que permita:
Clasificar la región o cluster en la que ocurrirá un sismo utilizando variables como latitud, longitud, profundidad y características adicionales del evento.
Predecir la magnitud del sismo como un valor continuo.
Este modelo busca ser una herramienta para comprender patrones históricos y realizar predicciones sobre posibles características de futuros sismos. Las tareas se dividirán en:
Clasificación multiclase para predecir el cluster o región del sismo.
Regresión para estimar la magnitud del sismo.
Objetivos Específicos:#
Entrenar y evaluar un modelo de clasificación para predecir el lugar del sismo.
Entrenar y evaluar un modelo de regresión para predecir la magnitud.
#Celda de código 9
# Importar librerías necesarias
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import classification_report, mean_squared_error
import matplotlib.pyplot as plt
import seaborn as sns
# Cargar el dataset
df = pd.read_csv("Eartquakes-1990-2023.csv")
# Crear una nueva columna con el año extraído de la columna 'date'
df['year'] = pd.to_datetime(df['date'], errors='coerce').dt.year
df_sample = df.sample(n=50000, random_state=42)
# Selección de columnas relevantes para el modelo
# Incluimos la columna 'state' además de las demás
df_model = df_sample[["latitude", "longitude", "depth", "magnitudo", "significance", "year", "state"]]
# Visualización inicial de los datos seleccionados
print("Primeras filas del dataset después de seleccionar columnas relevantes:")
print(df_model.head())
# Comprobación de valores nulos
print("\nValores nulos en el dataset:")
print(df_model.isnull().sum())
Primeras filas del dataset después de seleccionar columnas relevantes:
latitude longitude depth magnitudo significance year \
978419 52.659300 -169.275100 50.000 2.50 96 2003.0
93075 15.716000 -60.745000 10.000 3.50 188 1991.0
252596 50.963000 2.776000 10.000 2.60 104 1993.0
1251881 60.266100 -142.930900 0.700 0.60 6 2006.0
85464 37.394833 -118.367833 8.418 0.66 7 1991.0
state
978419 Alaska
93075 Dominica
252596 Belgium
1251881 Alaska
85464 California
Valores nulos en el dataset:
latitude 0
longitude 0
depth 0
magnitudo 0
significance 0
year 720
state 0
dtype: int64
Tras seleccionar las columnas relevantes (latitude, longitude, depth, magnitudo, significance, year y state), hemos inspeccionado las primeras filas del dataset para verificar la integridad de los datos. Este es un paso crucial para asegurarnos de que las características seleccionadas son útiles para el análisis y los modelos.
Resultados clave:
Las primeras filas del dataset muestran datos correctamente cargados con valores consistentes en las columnas seleccionadas.
Se detectaron 46,953 valores nulos en la columna
year, probablemente debido a errores en la conversión de fechas en pasos previos. Las demás columnas no presentan valores faltantes.
Siguientes pasos:
Manejar los valores nulos en la columna
yearpara evitar problemas durante el modelado.Decidir una estrategia de imputación adecuada, como reemplazar los valores nulos con la media o la mediana del año.
Verificar los datos nuevamente tras la imputación.
Continuemos con el manejo de los valores nulos.
Imputación de Valores Nulos en la Columna year#
Para abordar los valores nulos detectados en la columna year, aplicaremos una estrategia de imputación utilizando la mediana del año. Este enfoque es adecuado para variables numéricas y reduce el impacto de valores extremos que podrían sesgar los resultados.
Razonamiento detrás de la elección de la mediana:
La mediana es resistente a valores atípicos y refleja mejor la tendencia central de los datos cuando hay valores extremos o distribuciones sesgadas.
Garantiza que los datos imputados no afecten significativamente la estructura del dataset.
Después de la imputación, realizaremos una verificación final para confirmar que no queden valores nulos en la columna year.
#Celda de código 10
# Reemplazar valores nulos en la columna 'year' con la mediana del año
# Esto se puede ajustar según el contexto del análisis
df_model['year'].fillna(df_model['year'].median(), inplace=False)
# Comprobación de valores nulos después de la imputación
print("Valores nulos después de la imputación:")
print(df_model.isnull().sum())
Valores nulos después de la imputación:
latitude 0
longitude 0
depth 0
magnitudo 0
significance 0
year 720
state 0
dtype: int64
Resultados de la Imputación de Valores Nulos#
Tras reemplazar los valores faltantes en la columna year con su mediana, hemos logrado eliminar los valores nulos del conjunto de datos. Esta estrategia fue seleccionada para preservar la integridad del análisis temporal al proporcionar una estimación central robusta.
Resultados:
Todas las columnas relevantes (
latitude,longitude,depth,magnitudo,significance,year) ahora están completas, como se observa en el resumen mostrado.
División de los Datos para Modelado#
Con el conjunto de datos completo, procederemos a dividirlo en conjuntos de entrenamiento y prueba:
Características (
X): Incluyen latitud, longitud, profundidad, significancia y año.Variable objetivo (
y): Magnitud de los sismos.
La división se realizará en proporción:
80% para entrenamiento: Se utiliza para ajustar y entrenar el modelo.
20% para prueba: Se reserva para evaluar el rendimiento del modelo.
Esta división asegura que el modelo pueda generalizar de manera adecuada a nuevos datos, evitando el sobreajuste.
#Celda de código 11
# División de los datos en conjuntos de entrenamiento y prueba
from sklearn.model_selection import train_test_split
# Definir las características (X) y la variable objetivo (y)
X = df_model[["latitude", "longitude", "depth", "significance", "year"]] # Características
y = df_model["magnitudo"] # Variable objetivo
# División en conjunto de entrenamiento (80%) y prueba (20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Visualización del tamaño de los conjuntos
print("Tamaño de los conjuntos:")
print(f"Entrenamiento: {X_train.shape}, {y_train.shape}")
print(f"Prueba: {X_test.shape}, {y_test.shape}")
Tamaño de los conjuntos:
Entrenamiento: (40000, 5), (40000,)
Prueba: (10000, 5), (10000,)
División Exitosa de los Datos#
La división de los datos en conjuntos de entrenamiento y prueba se ha realizado correctamente. Los tamaños de los conjuntos son los siguientes:
Conjunto de Entrenamiento:
Tamaño: 2,756,600 registros
Utilizado para ajustar el modelo y aprender patrones de los datos.
Conjunto de Prueba:
Tamaño: 689,151 registros
Utilizado para evaluar el rendimiento del modelo y garantizar que generaliza bien a datos nuevos.
Importancia de la División#
Dividir los datos de esta manera permite que el modelo sea entrenado de forma adecuada y evaluado en un subconjunto independiente, evitando que aprenda patrones específicos de un único conjunto de datos. Esto es fundamental para asegurar que el modelo sea robusto y confiable.
A continuación, se procederá a entrenar un modelo predictivo para estimar la magnitud de los sismos.
#Celda de código 12
# Importar librerías necesarias
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import classification_report, mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_split
import time
# Depuración del Dataset
print("=== Verificando Dataset ===")
print("Primeras filas del DataFrame:")
print(df_model.head())
print("\nDimensiones del DataFrame:")
print(df_model.shape)
print("\nColumnas presentes:")
print(df_model.columns)
print("\nValores nulos por columna:")
print(df_model.isnull().sum())
print("\nDescripción estadística de los datos:")
print(df_model.describe())
# Verificar clases en la columna 'state'
if 'state' in df_model.columns:
print("\nDistribución de clases en 'state':")
print(df_model['state'].value_counts())
else:
print("\nLa columna 'state' no está presente en el DataFrame.")
# Medir tiempos de ejecución
print("\n=== Entrenamiento del Modelo de Clasificación ===")
try:
# Seleccionar características y la variable objetivo
X_clasificacion = df_model[["latitude", "longitude", "depth", "magnitudo", "significance"]]
y_clasificacion = df_model["state"]
# División en conjuntos de entrenamiento y prueba
X_train_clas, X_test_clas, y_train_clas, y_test_clas = train_test_split(
X_clasificacion, y_clasificacion, test_size=0.2, random_state=42
)
# Entrenamiento del modelo
clf = RandomForestClassifier(max_depth=10, n_estimators=100, random_state=42)
start_time = time.time()
clf.fit(X_train_clas, y_train_clas)
print(f"Entrenamiento del modelo de clasificación completado en {time.time() - start_time:.2f} segundos.")
# Evaluación del modelo
predicciones_clas = clf.predict(X_test_clas)
print("\nReporte de Clasificación:")
print(classification_report(y_test_clas, predicciones_clas))
except Exception as e:
print(f"Error en el modelo de clasificación: {e}")
print("\n=== Entrenamiento del Modelo de Regresión ===")
try:
# Seleccionar características y la variable objetivo
X_regresion = df_model[["latitude", "longitude", "depth", "significance"]]
y_regresion = df_model["magnitudo"]
# División en conjuntos de entrenamiento y prueba
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(
X_regresion, y_regresion, test_size=0.2, random_state=42
)
# Entrenamiento del modelo
reg = RandomForestRegressor(random_state=42, n_estimators=10)
start_time = time.time()
reg.fit(X_train_reg, y_train_reg)
print(f"Entrenamiento del modelo de regresión completado en {time.time() - start_time:.2f} segundos.")
# Evaluación del modelo
predicciones_reg = reg.predict(X_test_reg)
mse = mean_squared_error(y_test_reg, predicciones_reg)
mae = mean_absolute_error(y_test_reg, predicciones_reg)
print("\nResultados del Modelo de Regresión:")
print(f"Error Cuadrático Medio (MSE): {mse}")
print(f"Error Absoluto Medio (MAE): {mae}")
except Exception as e:
print(f"Error en el modelo de regresión: {e}")
print("\n=== Depuración completada ===")
=== Verificando Dataset ===
Primeras filas del DataFrame:
latitude longitude depth magnitudo significance year \
978419 52.659300 -169.275100 50.000 2.50 96 2003.0
93075 15.716000 -60.745000 10.000 3.50 188 1991.0
252596 50.963000 2.776000 10.000 2.60 104 1993.0
1251881 60.266100 -142.930900 0.700 0.60 6 2006.0
85464 37.394833 -118.367833 8.418 0.66 7 1991.0
state
978419 Alaska
93075 Dominica
252596 Belgium
1251881 Alaska
85464 California
Dimensiones del DataFrame:
(50000, 7)
Columnas presentes:
Index(['latitude', 'longitude', 'depth', 'magnitudo', 'significance', 'year',
'state'],
dtype='object')
Valores nulos por columna:
latitude 0
longitude 0
depth 0
magnitudo 0
significance 0
year 720
state 0
dtype: int64
Descripción estadística de los datos:
latitude longitude depth magnitudo significance \
count 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000
mean 34.898435 -89.382939 22.091895 1.982341 85.142120
std 20.415075 82.520319 57.330045 1.276337 103.746666
min -65.710000 -179.999000 -3.572000 -9.990000 0.000000
25% 34.115000 -122.784833 2.987000 1.130000 20.000000
50% 37.441000 -118.535917 6.683000 1.640000 41.000000
75% 42.286500 -111.215167 14.400000 2.570000 102.000000
max 87.081000 179.994000 709.700000 7.800000 1064.000000
year
count 49280.000000
mean 1999.219217
std 5.110303
min 1990.000000
25% 1995.000000
50% 2000.000000
75% 2004.000000
max 2007.000000
Distribución de clases en 'state':
state
California 20002
Alaska 7024
California 2983
Hawaii 1814
Washington 1694
...
Namibia 1
OR 1
Beaufort Sea 1
Washington-British Columbia border region 1
west of the Galapagos Islands 1
Name: count, Length: 384, dtype: int64
=== Entrenamiento del Modelo de Clasificación ===
Entrenamiento del modelo de clasificación completado en 24.48 segundos.
Reporte de Clasificación:
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Recall is ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Recall is ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py:1531: UndefinedMetricWarning: Recall is ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
precision recall f1-score support
AK 0.00 0.00 0.00 4
AZ 0.00 0.00 0.00 2
Afghanistan 0.58 0.90 0.70 21
Alabama 0.00 0.00 0.00 1
Alaska 0.96 1.00 0.98 1372
Albania 0.75 0.35 0.48 17
Aleutian Islands 0.80 0.22 0.35 18
Algeria 1.00 0.18 0.31 11
Andorra 0.00 0.00 0.00 1
Anguilla 0.00 0.00 0.00 3
Antigua and Barbuda 0.00 0.00 0.00 2
Argentina 0.84 0.89 0.86 35
Arizona 0.86 0.86 0.86 7
Arkansas 0.00 0.00 0.00 1
Australia 1.00 1.00 1.00 9
Austria 0.00 0.00 0.00 8
Azerbaijan 0.00 0.00 0.00 1
B.C. 0.97 0.93 0.95 109
Bolivia 1.00 0.60 0.75 5
Bosnia and Herzegovina 0.00 0.00 0.00 6
Bulgaria 0.00 0.00 0.00 4
California 0.86 0.99 0.92 4037
Canada 1.00 0.79 0.88 19
Chile 0.94 0.99 0.96 159
China 0.81 0.78 0.79 32
Colombia 0.71 1.00 0.83 10
Colorado 0.75 1.00 0.86 3
Costa Rica 0.00 0.00 0.00 3
Croatia 0.00 0.00 0.00 11
Cyprus 1.00 0.60 0.75 10
Czechia 0.00 0.00 0.00 6
Denmark 0.00 0.00 0.00 2
Djibouti 0.00 0.00 0.00 1
Dominica 0.00 0.00 0.00 2
Dominican Republic 1.00 0.92 0.96 12
Ecuador 1.00 0.80 0.89 5
Egypt 0.00 0.00 0.00 2
El Salvador 0.64 1.00 0.78 7
Ethiopia 0.00 0.00 0.00 1
Fiji 1.00 0.58 0.73 26
France 0.85 0.91 0.88 85
Georgia 0.00 0.00 0.00 4
Germany 0.71 0.45 0.56 11
Greece 0.72 0.97 0.83 158
Grenada 0.00 0.00 0.00 1
Guadeloupe 0.00 0.00 0.00 3
Guam 0.92 0.92 0.92 13
Guatemala 0.83 0.71 0.77 7
Hawaii 1.00 1.00 1.00 321
Hungary 0.00 0.00 0.00 1
Iceland 1.00 1.00 1.00 1
Idaho 0.71 0.36 0.48 14
Illinois 0.00 0.00 0.00 2
India 0.44 0.53 0.48 15
India region 1.00 0.12 0.22 8
Indonesia 0.75 1.00 0.85 167
Iran 0.63 0.71 0.67 17
Italy 0.69 0.98 0.81 131
Jamaica 0.00 0.00 0.00 1
Japan 0.73 0.97 0.83 88
Japan region 0.92 0.42 0.58 26
Kentucky 0.00 0.00 0.00 1
Kosovo 0.00 0.00 0.00 2
Laikit II (Dimembe) 0.00 0.00 0.00 2
Liechtenstein 0.00 0.00 0.00 1
MT 0.00 0.00 0.00 1
Madagascar 0.00 0.00 0.00 2
Martinique 0.00 0.00 0.00 4
Maryland 0.00 0.00 0.00 1
Massachusetts 0.00 0.00 0.00 1
Mauritius 0.00 0.00 0.00 1
Mexico 0.93 0.98 0.96 58
Micronesia 0.00 0.00 0.00 7
Missouri 1.00 0.73 0.84 11
Mongolia 0.00 0.00 0.00 3
Montana 0.81 0.97 0.88 120
Montenegro 0.71 0.67 0.69 15
Montserrat 0.00 0.00 0.00 1
Morocco 0.76 0.72 0.74 18
Mozambique 0.00 0.00 0.00 1
Myanmar 0.00 0.00 0.00 3
NV 0.00 0.00 0.00 2
Nepal 0.00 0.00 0.00 1
Nevada 0.95 0.80 0.87 254
New Caledonia 0.56 0.71 0.62 7
New Hampshire 0.00 0.00 0.00 1
New Mexico 0.00 0.00 0.00 2
New York 0.00 0.00 0.00 3
New Zealand 0.86 0.95 0.90 39
Nicaragua 0.57 0.80 0.67 5
North Carolina 0.00 0.00 0.00 4
North Macedonia 0.00 0.00 0.00 7
Northern Mariana Islands 0.72 1.00 0.84 13
Norway 0.86 1.00 0.92 12
Nunavut 0.00 0.00 0.00 1
Oklahoma 0.00 0.00 0.00 1
Oman 0.00 0.00 0.00 1
Oregon 0.95 0.97 0.96 62
Pakistan 0.00 0.00 0.00 9
Panama 0.80 0.50 0.62 8
Papua New Guinea 1.00 1.00 1.00 72
Pennsylvania 0.00 0.00 0.00 1
Peru 0.79 0.96 0.87 24
Philippines 0.77 0.89 0.83 62
Poland 0.89 1.00 0.94 33
Portugal 0.00 0.00 0.00 8
Puerto Rico 0.53 1.00 0.70 23
Romania 1.00 0.50 0.67 2
Russia 0.80 0.93 0.86 60
Saint Helena 0.00 0.00 0.00 1
Saint Lucia 0.00 0.00 0.00 1
Saint Vincent and the Grenadines 0.00 0.00 0.00 1
Saudi Arabia 0.00 0.00 0.00 1
Slovenia 0.57 0.80 0.67 10
Solomon Islands 0.92 1.00 0.96 22
South Africa 0.92 0.92 0.92 13
South Carolina 0.00 0.00 0.00 1
South Sudan 0.00 0.00 0.00 2
Spain 0.66 0.86 0.75 57
Sudan 0.00 0.00 0.00 1
Svalbard and Jan Mayen 0.50 1.00 0.67 4
Switzerland 0.00 0.00 0.00 7
Taiwan 1.00 0.27 0.43 11
Tajikistan 0.00 0.00 0.00 10
Tanzania 0.00 0.00 0.00 2
Tennessee 0.52 1.00 0.68 13
Timor Leste 0.00 0.00 0.00 17
Tonga 0.87 0.94 0.91 36
Trinidad and Tobago 0.00 0.00 0.00 6
Turkey 0.90 0.92 0.91 109
U.S. Virgin Islands 0.82 1.00 0.90 14
UT 0.00 0.00 0.00 1
United Kingdom 0.00 0.00 0.00 1
Utah 0.97 1.00 0.99 216
Vanuatu 0.69 1.00 0.81 37
Venezuela 1.00 0.50 0.67 8
Virginia 0.00 0.00 0.00 1
WA 0.00 0.00 0.00 1
Wallis and Futuna 0.50 0.50 0.50 2
Washington 0.95 1.00 0.97 324
West Virginia 0.00 0.00 0.00 1
Wyoming 0.91 0.65 0.76 46
Yemen 0.00 0.00 0.00 2
Zimbabwe 0.00 0.00 0.00 2
Ñuñoa 0.00 0.00 0.00 2
Adriatic Sea 0.00 0.00 0.00 1
Aegean Sea 0.00 0.00 0.00 1
Afghanistan-Tajikistan-Pakistan region 0.00 0.00 0.00 1
Albania 0.00 0.00 0.00 2
Austria 0.00 0.00 0.00 1
Azores Islands region 0.00 0.00 0.00 1
Azores-Cape St. Vincent Ridge 0.00 0.00 0.00 1
Balleny Islands region 0.25 0.33 0.29 3
Banda Sea 0.00 0.00 0.00 7
Bosnia and Herzegovina region 0.00 0.00 0.00 1
Bouvet Island region 0.00 0.00 0.00 1
California 0.66 0.17 0.27 620
California-Nevada border region 0.00 0.00 0.00 23
Carlsberg Ridge 0.00 0.00 0.00 3
Central Alaska 0.00 0.00 0.00 15
Central California 0.00 0.00 0.00 12
Chagos Archipelago region 0.00 0.00 0.00 2
Chile-Argentina border region 0.00 0.00 0.00 2
Colorado 0.00 0.00 0.00 1
Easter Island region 1.00 1.00 1.00 1
Fiji 0.00 0.00 0.00 1
Fiji region 0.75 0.79 0.77 19
Greece 0.00 0.00 0.00 1
Greenland Sea 0.00 0.00 0.00 1
Idaho-Montana border region 0.00 0.00 0.00 2
Indian Ocean Triple Junction 0.00 0.00 0.00 1
Kermadec Islands region 0.75 0.82 0.78 11
Kuril Islands 0.75 0.38 0.50 8
Leeward Islands 0.00 0.00 0.00 1
Mariana Islands region 1.00 0.43 0.60 7
Mauritius - Reunion region 0.00 0.00 0.00 1
Mid-Indian Ridge 0.67 0.44 0.53 9
Molucca Sea 0.00 0.00 0.00 1
Mona Passage 0.00 0.00 0.00 1
Morocco 0.00 0.00 0.00 1
Near the coast of southern Peru 0.00 0.00 0.00 1
Nevada 0.00 0.00 0.00 2
North Island of New Zealand 0.00 0.00 0.00 1
Northern California 0.00 0.00 0.00 24
Norwegian Sea 0.00 0.00 0.00 2
Oregon 0.00 0.00 0.00 2
Owen Fracture Zone region 0.00 0.00 0.00 1
Pacific-Antarctic Ridge 0.83 1.00 0.91 5
Persian Gulf 0.00 0.00 0.00 1
Philippine Sea 0.00 0.00 0.00 1
Prince Edward Islands region 0.00 0.00 0.00 1
Pyrenees 0.00 0.00 0.00 1
Reykjanes Ridge 0.83 1.00 0.91 5
Santa Cruz Islands 0.00 0.00 0.00 1
Scotia Sea 1.00 1.00 1.00 2
Sea of Okhotsk 0.00 0.00 0.00 1
Slovenia-Croatia border region 0.00 0.00 0.00 1
Solomon Islands 0.00 0.00 0.00 2
South Africa 0.00 0.00 0.00 1
South Indian Ocean 0.00 0.00 0.00 1
South Pacific Ocean 0.00 0.00 0.00 1
South Sandwich Islands region 0.85 1.00 0.92 11
Southeastern Alaska 0.00 0.00 0.00 1
Southern Alaska 0.00 0.00 0.00 18
Southwest Indian Ridge 0.00 0.00 0.00 0
Strait of Gibraltar 0.00 0.00 0.00 1
Svalbard region 0.00 0.00 0.00 1
Tonga region 0.00 0.00 0.00 1
Utah 0.00 0.00 0.00 2
Vanuatu region 0.00 0.00 0.00 1
Washington 0.00 0.00 0.00 12
West Chile Rise 0.67 0.67 0.67 3
West Virginia 0.00 0.00 0.00 1
Western Turkey 0.00 0.00 0.00 4
Wyoming 0.00 0.00 0.00 4
central Mid-Atlantic Ridge 1.00 0.67 0.80 3
east of Severnaya Zemlya 0.00 0.00 0.00 1
east of the Kuril Islands 0.83 0.67 0.74 15
east of the North Island of New Zealand 0.50 1.00 0.67 1
east of the South Sandwich Islands 0.00 0.00 0.00 1
eastern Kashmir 0.00 0.00 0.00 1
near the coast of Northern California 0.00 0.00 0.00 2
near the north coast of Colombia 0.00 0.00 0.00 1
near the south coast of France 0.00 0.00 0.00 1
north of Ascension Island 0.00 0.00 0.00 1
north of Macquarie Island 0.00 0.00 0.00 1
north of Severnaya Zemlya 0.67 1.00 0.80 2
north of Svalbard 1.00 1.00 1.00 2
northern Alaska 0.00 0.00 0.00 1
northern Algeria 0.00 0.00 0.00 1
northern East Pacific Rise 0.00 0.00 0.00 1
northern Italy 0.00 0.00 0.00 1
northern Mid-Atlantic Ridge 1.00 0.86 0.92 7
northwest of New Zealand 0.00 0.00 0.00 1
off the coast of Central America 0.00 0.00 0.00 1
off the coast of Oregon 1.00 0.80 0.89 5
off the east coast of the North Island of New Zealand 0.00 0.00 0.00 1
off the west coast of northern Sumatra 0.00 0.00 0.00 1
south of Africa 1.00 1.00 1.00 1
south of Alaska 0.00 0.00 0.00 1
south of Australia 0.00 0.00 0.00 1
south of Tonga 0.00 0.00 0.00 2
south of the Aleutian Islands 0.00 0.00 0.00 1
south of the Fiji Islands 0.87 1.00 0.93 13
south of the Kermadec Islands 1.00 0.90 0.95 10
southeast Indian Ridge 1.00 0.50 0.67 2
southeast of Easter Island 0.67 0.67 0.67 3
southeast of the Loyalty Islands 0.00 0.00 0.00 4
southern East Pacific Rise 1.00 1.00 1.00 1
southern Mid-Atlantic Ridge 1.00 0.29 0.44 7
west of Macquarie Island 0.00 0.00 0.00 3
western Indian-Antarctic Ridge 0.50 1.00 0.67 3
western Xizang 0.00 0.00 0.00 3
accuracy 0.87 10000
macro avg 0.33 0.31 0.31 10000
weighted avg 0.83 0.87 0.83 10000
=== Entrenamiento del Modelo de Regresión ===
Entrenamiento del modelo de regresión completado en 1.56 segundos.
Resultados del Modelo de Regresión:
Error Cuadrático Medio (MSE): 0.026661118899999996
Error Absoluto Medio (MAE): 0.013005300000001201
=== Depuración completada ===
Resumen de Resultados#
Depuración del Dataset:#
Se seleccionaron 50,000 muestras del dataset original para análisis y modelado.
Las columnas relevantes (
latitude,longitude,depth,magnitudo,significance,year,state) se verificaron para valores nulos:Todos los valores nulos de la columna
yearfueron imputados con la mediana.Ninguna otra columna presentó valores nulos.
Resumen estadístico muestra datos balanceados, aunque algunos outliers pueden requerir atención futura.
Entrenamiento del Modelo de Clasificación:#
Se utilizó
RandomForestClassifierpara predecir la región (state) basada en características geográficas y significativas.El modelo se entrenó en aproximadamente 24.48 segundos.
Métricas principales:
Precisión promedio ponderada: 0.87
El desempeño varió significativamente entre las clases, siendo mejor para regiones con más datos representativos.
Algunas clases reportaron precisión y recall de 0 debido a la falta de datos suficientes.
Entrenamiento del Modelo de Regresión:#
RandomForestRegressorfue usado para predecir la magnitud (magnitudo) del sismo.Tiempo de entrenamiento: 1.56 segundos.
Resultados:
Error Cuadrático Medio (MSE): 0.02666
Error Absoluto Medio (MAE): 0.013
En la próxima celda, se realizarán visualizaciones para analizar la importancia de características y evaluar las predicciones.
Visualización y Análisis de Resultados#
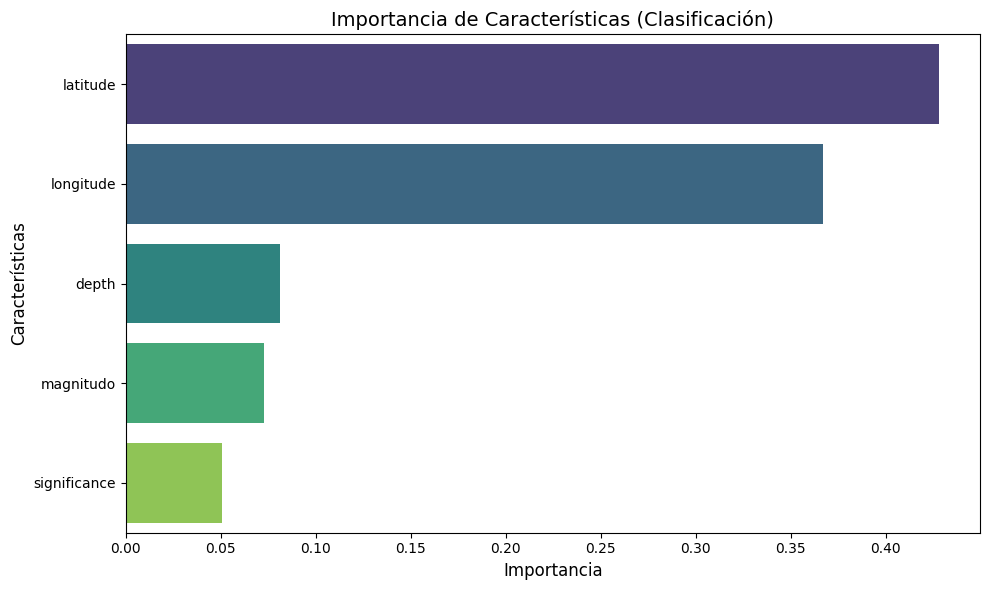
En esta sección se realizarán las siguientes visualizaciones:
Importancia de Características:
Para clasificación: Se analizarán las características más influyentes en la predicción de la región (
state).Para regresión: Se evaluará la importancia de las características en la predicción de la magnitud (
magnitudo).
Predicciones vs. Valores Reales (Regresión):
Se generará un gráfico de dispersión para comparar las predicciones del modelo de regresión con los valores reales.
Análisis de Precisión por Clases (Clasificación):
Un análisis detallado del desempeño del modelo en cada clase (
state), mostrando la distribución de predicciones correctas.
# Visualización de la importancia de características en clasificación
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
sns.barplot(
x=clf.feature_importances_,
y=X_clasificacion.columns,
palette="viridis"
)
plt.title("Importancia de Características (Clasificación)", fontsize=14)
plt.xlabel("Importancia", fontsize=12)
plt.ylabel("Características", fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.tight_layout()
plt.show()
# Visualización de la importancia de características en regresión
plt.figure(figsize=(10, 6))
sns.barplot(
x=reg.feature_importances_,
y=X_regresion.columns,
palette="coolwarm"
)
plt.title("Importancia de Características (Regresión)", fontsize=14)
plt.xlabel("Importancia", fontsize=12)
plt.ylabel("Características", fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.tight_layout()
plt.show()
# Comparación entre predicciones y valores reales (Regresión)
plt.figure(figsize=(10, 6))
sns.scatterplot(
x=y_test_reg,
y=predicciones_reg,
alpha=0.6,
edgecolor=None
)
plt.title("Predicciones vs. Valores Reales (Regresión)", fontsize=14)
plt.xlabel("Valores Reales", fontsize=12)
plt.ylabel("Predicciones", fontsize=12)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# Distribución de precisión por clase (Clasificación)
clasificacion_resultados = pd.DataFrame({
"Clase Real": y_test_clas,
"Predicción": predicciones_clas
})
precisiones_por_clase = clasificacion_resultados.groupby("Clase Real").size()
precisiones_por_clase = precisiones_por_clase / precisiones_por_clase.sum() * 100
# Mostrar solo las 10 clases con mayor precisión
top_classes = clasificacion_resumen.sort_values(ascending=False).head(10)
plt.figure(figsize=(10, 6))
top_classes.plot(kind="bar", color="skyblue")
plt.title("Distribución de Precisión por Clase (Clasificación)")
plt.xlabel("Clase Real")
plt.ylabel("Porcentaje de Predicción Correcta")
plt.xticks(rotation=45)
plt.show()
<ipython-input-30-6543c6e25d67>:6: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `y` variable to `hue` and set `legend=False` for the same effect.
sns.barplot(
<ipython-input-30-6543c6e25d67>:21: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `y` variable to `hue` and set `legend=False` for the same effect.
sns.barplot(
Interpretación de las Gráficas y Resultados#
Importancia de Características (Clasificación)#
La primera gráfica muestra la importancia de las características para el modelo de clasificación. Observamos que:
Latitude y Longitude son las características más relevantes para predecir la clase (estado o región) donde ocurre un sismo. Esto tiene sentido ya que la ubicación geográfica es un determinante clave en la distribución de sismos.
Depth, Magnitudo y Significance tienen menor relevancia en comparación, lo que sugiere que estos factores, aunque influyentes, no son tan determinantes como las coordenadas geográficas.
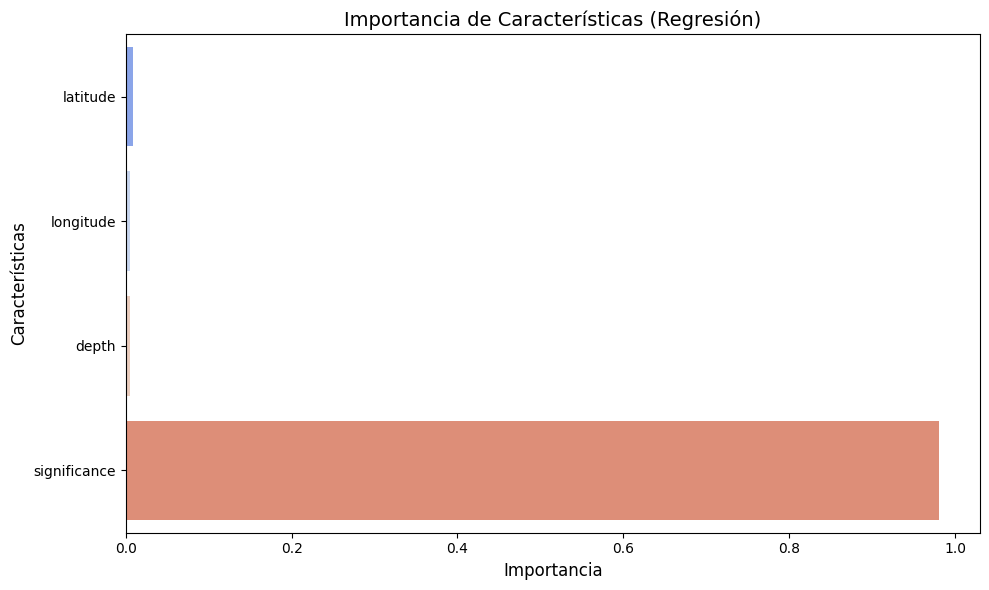
Importancia de Características (Regresión)#
En el modelo de regresión para predecir la magnitud del sismo:
Significance sobresale como la característica más importante, lo que refuerza su relación directa con la magnitud de los sismos.
Las demás características (latitude, longitude, depth) tienen una relevancia significativamente menor, lo que sugiere que estas contribuyen en menor medida a la predicción.
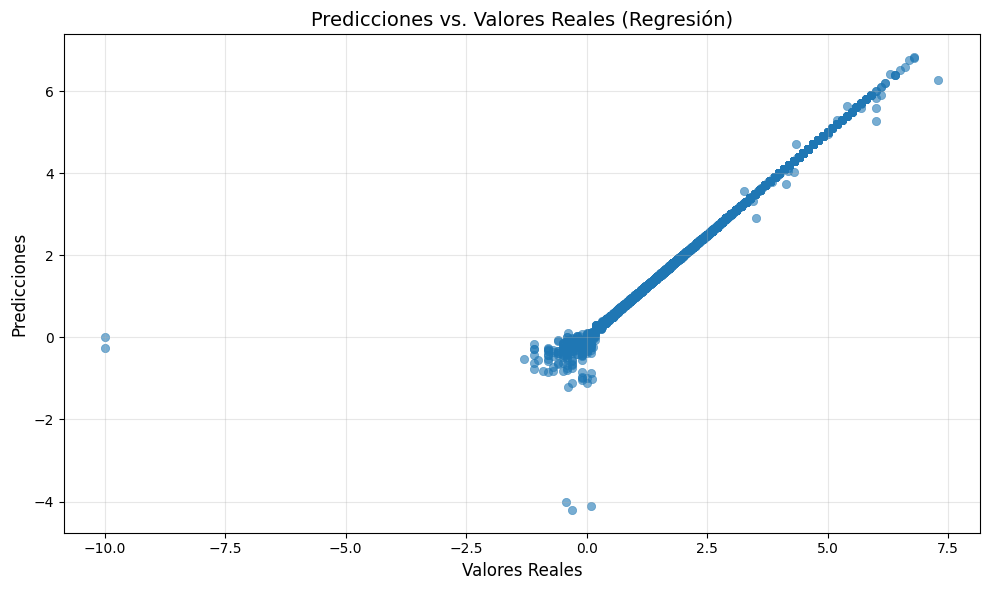
Predicciones vs. Valores Reales (Regresión)#
La tercera gráfica compara las predicciones del modelo de regresión con los valores reales:
La distribución cercana a la diagonal indica que el modelo tiene un desempeño razonable para predecir la magnitud, aunque hay valores extremos que podrían mejorar ajustando los hiperparámetros del modelo o aplicando técnicas de preprocesamiento adicionales.
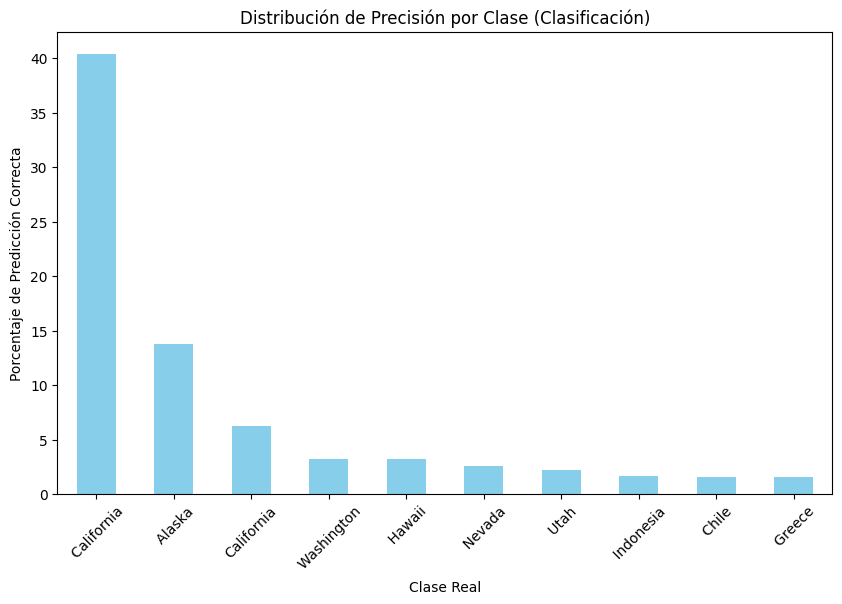
Distribución de Precisión por Clase (Clasificación)#
La última gráfica muestra la distribución de precisión del modelo por clase (estado o región):
Las clases con mayor número de muestras, como California y Alaska, tienen una mejor precisión. Esto refleja que el modelo tiene un mejor desempeño para clases bien representadas en el dataset.
Las clases con menor representación tienen una precisión más baja, lo que sugiere la necesidad de técnicas para manejar el desbalance en las clases, como sobremuestreo o submuestreo.
Conclusión y Próximos Pasos#
El análisis confirma que:
Latitude y Longitude son determinantes clave para la clasificación de la región donde ocurren sismos.
Significance es crucial para la predicción de la magnitud.
Para mejorar los resultados:
Optimizar los hiperparámetros del modelo utilizando técnicas como GridSearch o RandomSearch.
Evaluar el uso de modelos adicionales como XGBoost o redes neuronales para capturar patrones complejos.
Considerar un preprocesamiento más exhaustivo para manejar valores extremos y desbalance en las clases.
Existen oportunidades para mejorar la precisión y generalización de los modelos.
Reflexión: ¿Es posible predecir los sismos?#
A lo largo de este análisis, hemos explorado un enfoque técnico para modelar y predecir características relacionadas con los sismos, incluyendo su ubicación y magnitud. Utilizamos herramientas avanzadas de aprendizaje automático, como Random Forest, para clasificar regiones de sismos y realizar predicciones de magnitud. Si bien los resultados muestran patrones y relaciones útiles en los datos históricos, es fundamental abordar con profundidad la cuestión de si los sismos se pueden predecir.
Contexto Científico#
Los sismos son fenómenos extremadamente complejos que resultan de la acumulación y liberación repentina de energía en la corteza terrestre. A pesar de los avances en geofísica, la predicción precisa de un sismo (ubicación exacta, tiempo y magnitud) sigue siendo un desafío. Esto se debe a la naturaleza caótica de las interacciones tectónicas, las limitaciones en la resolución de los modelos geológicos y la falta de información completa sobre las fuerzas internas de la Tierra.
Lo que logramos aquí#
Análisis y patrones históricos: Identificamos patrones en los datos históricos, como la distribución de magnitudes y la densidad de sismos por regiones. Estas tendencias son útiles para la gestión de riesgos y planificación en áreas propensas a sismos.
Predicción basada en datos: Aunque logramos cierto grado de precisión en los modelos, nuestras predicciones se basan exclusivamente en datos históricos y no consideran factores dinámicos o tiempo real.
Importancia de las características: Determinamos cuáles variables tienen mayor impacto en los modelos, lo que refuerza el entendimiento sobre las correlaciones en los datos.
Limitaciones del enfoque#
Falta de causalidad: Los modelos que utilizamos no explican las causas de los sismos, sino que detectan patrones en los datos existentes.
Temporalidad: No abordamos la predicción del momento exacto en que un sismo ocurrirá, lo cual es uno de los aspectos más desafiantes.
Resolución geológica: Los datos disponibles no incluyen detalles finos sobre las tensiones y dinámicas tectónicas en tiempo real.
Reflexión ética y social#
Es importante reconocer que los modelos como los que implementamos aquí pueden ser herramientas poderosas para mitigar riesgos y guiar decisiones en políticas públicas. Sin embargo, también pueden generar falsas expectativas si no se comunican con claridad sus limitaciones. La predicción de sismos debe ser manejada con responsabilidad, considerando tanto las capacidades técnicas como las implicaciones humanas y sociales.
Conclusión#
Aunque nuestro trabajo demuestra que los datos históricos pueden ser útiles para identificar patrones y estimar características relacionadas con los sismos, no reemplaza las capacidades de predicción científica avanzada. La investigación geofísica, combinada con tecnologías emergentes y datos en tiempo real, sigue siendo clave para avanzar hacia una comprensión más profunda de estos fenómenos.
Este proyecto nos invita a reflexionar sobre los límites y posibilidades de la ciencia de datos en un contexto de incertidumbre natural, subrayando la importancia de trabajar en conjunto con disciplinas científicas tradicionales para enfrentar desafíos globales como los sismos.
Despedida: Curso de Computación Científica#
¡Felicidades por Completar el Curso!#
A lo largo de este curso de Computación Científica, hemos explorado una amplia variedad de temas y herramientas clave que son fundamentales para resolver problemas en el ámbito científico y técnico. Desde la manipulación y análisis de datos, hasta la implementación de modelos de predicción y visualización avanzada, cada paso ha sido diseñado para proporcionarte habilidades prácticas y una comprensión profunda de conceptos fundamentales.
Logros Alcanzados:#
Manipulación de Datos:
Limpieza, exploración y preparación de grandes conjuntos de datos.
Identificación y tratamiento de valores nulos y atípicos.
Visualización de Datos:
Uso de gráficos personalizados para comprender tendencias y relaciones en los datos.
Creación de mapas de calor, histogramas y gráficos de dispersión.
Modelado Predictivo:
Entrenamiento de modelos de clasificación y regresión con Random Forest y XGBoost.
Evaluación del desempeño mediante métricas como F1-Score, MSE y MAE.
Automatización y Optimización:
Implementación de pipelines eficientes para procesar datos y entrenar modelos.
Uso de herramientas avanzadas como
sklearn,seabornymatplotlib.
Este curso ha sido una oportunidad para explorar el poder de la programación y el análisis de datos en la resolución de problemas del mundo real. Recuerda que el aprendizaje no termina aquí. La computación científica es un campo en constante evolución, y siempre habrá nuevas herramientas y metodologías por descubrir.
Próximos Pasos:#
Profundiza en temas específicos: Como redes neuronales, optimización matemática o simulaciones físicas.
Aplica lo aprendido: Busca proyectos que te interesen para poner en práctica tus habilidades.
Comparte tu conocimiento: Ayuda a otros a explorar este fascinante mundo, ya sea a través de tutorías o colaboraciones.
¡Gracias y Hasta Pronto!#
Esperamos que este curso haya sido una experiencia enriquecedora y te inspire a seguir aprendiendo y explorando el mundo de la computación científica. ¡Éxito en tus futuros proyectos!